
Soirée JUG Nantes : Du SQL au NoSQL en moins d'une heure (Partie 2)
Vous pouvez retrouvez la première partie de cet article ici.
Le 04 novembre dernier, Tugdual Grall et David Pilato ont offert au public nantais une preview d’une session qu’ils allaient donner quelques jours plus tard à Devoxx Belgique. Ils vont montrer, sur la base d’une application exemple, une migration du SQL au monde du NoSQL.
Pourquoi passer du SQL au NoSQL ?
Tugdual et David vont commencer la session par présenter LA raison qui pourrait vous convaincre de migrer d’une base SQL à une base NoSQL : la scalabilité horizontale.
Scalabilité horizontale sont les mots à la mode pour désigner la caractéristique d’un système capable de supporter une grande charge. Pour augmenter la puissance d’un système, sa stratégie consiste à multiplier le nombre de machines de petites puissances. Elle se positionne en opposition à la scalabilité verticale qui prône l’augmentation des capacités d’une machine pour répondre à des besoins de charge croissants.
La scalabilité horizontale s’impose de plus en plus comme LA solution pour relever le défi des systèmes performants à fort trafic.
Peut-on effectuer la scalabilité horizontale avec une base de données relationnelle ?
La réponse est oui. Ca s’appelle mettre en place un cluster de base de données. Tug et David vont demander aux participants combien avaient déjà configuré un cluster de bases de données relationnelles ? Je n’ai vu qu’une seule main levée de là où j’étais assis. Cette opération requiert des compétences assez pointues pour obtenir un système fonctionnel.
Et le NoSQL dans tout ça ?
Tug et David vont promettre que cette opération qui nécessitait la présence d’un administrateur de bases de données très expérimenté va être accessible aux développeurs. Cette promesse sera accompagnée d’une démonstration :
- du passage d’un modèle dit legacy à un modèle moderne REST
- du passage d’un modèle SQL à un modèle NoSQL
- de distribution de données sur plusieurs noeuds
- de la mise en place d’une recherche full text sur des données distribuées
- de visualisation des données distribuées suivant des axes configurables
L’intégralité des sources de la démonstration est accessible dans le dépôt Github sql2nosql. La version des sources correspondante à une étape est accessible via les branches du dépôt.
A partir de ce dépôt, je vais effectuer toutes les étapes sur ma machine.
Allons y !
Récupération des sources
Je vais commencer par récupérer le contenu de la branche 01-legacy/start.
Pour ceux qui voudraient faire autant et qui ne sont pas familier de Github, voici quelques alternatives :
1
2
git clone https://github.com/dadoonet/sql2nosql.git
git checkout 01-legacy/start
-
Installer le client officiel correspondant à votre OS : Windows, Mac. Pour linux ? Vous connaissez la chanson, si vous êtes sous linux c’est que vous ne jurez que par le terminal, faites comme d’habitude utiliser la ligne de commande ;) Il existe des clients graphiques non officiels mais je n’ai rien à vous recommander, j’ai pris l’habitude de la ligne de commande pour Git même si j’utilise un client graphique quand il s’agit de SVN. Il n’y a pas de raison particulière, question d’habitude.
-
Installer Subversion et exécuter la commande suivante pour récupérer l’intégralité des sources. Vous pouvez aussi passer par des clients graphiques comme TortoiseSVN. Les sources se trouveront dans le répertoire sql2nosql/branches/01-legacy.
1
svn co https://github.com/dadoonet/sql2nosql
Exécution de l’application
L’architecture de l’application repose sur Maven. J’ai utilisé la version 3.1.1 pour écrire cet article.
Pour exécuter l’application :
-
Si vous êtes sous linux ou Mac, lancer le script
run.sh -
Si vous êtes sous Windows, lancer les commandes :
1
2
3
mvn clean install
cd demo-webapp
mvn jetty:run
Si l’application ne parvient pas à récupérer le plugin Maven pour Jetty.
Créer/compléter la configuration du fichier ~/.m2/settings.xml dans la section pluginGroups comme ceci :
1
2
3
4
5
<settings>
<pluginGroups>
<pluginGroup>org.eclipse.jetty</pluginGroup>
</pluginGroups>
</settings>
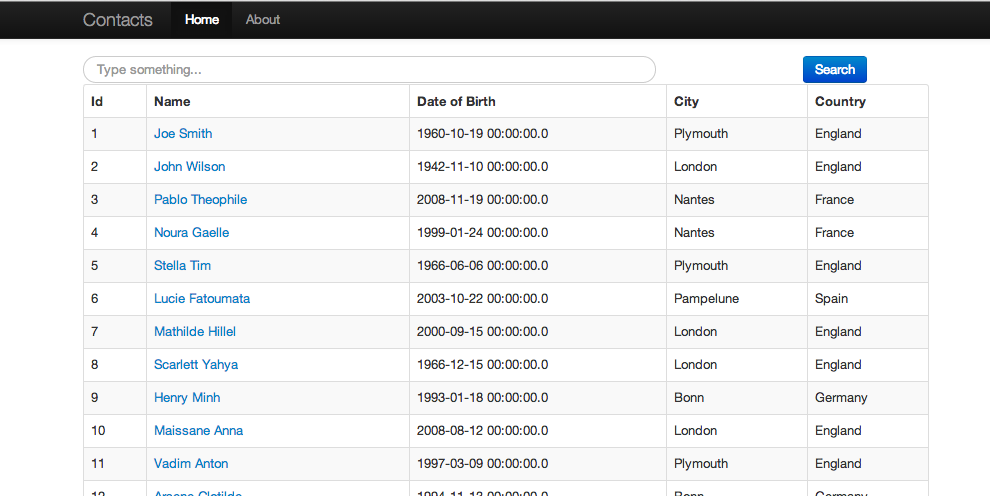
Une fois l’application démarrée, vous pouvez accéder à la page d’accueil via l’adresse : http://localhost:8080. Elle affiche une liste de personnes.
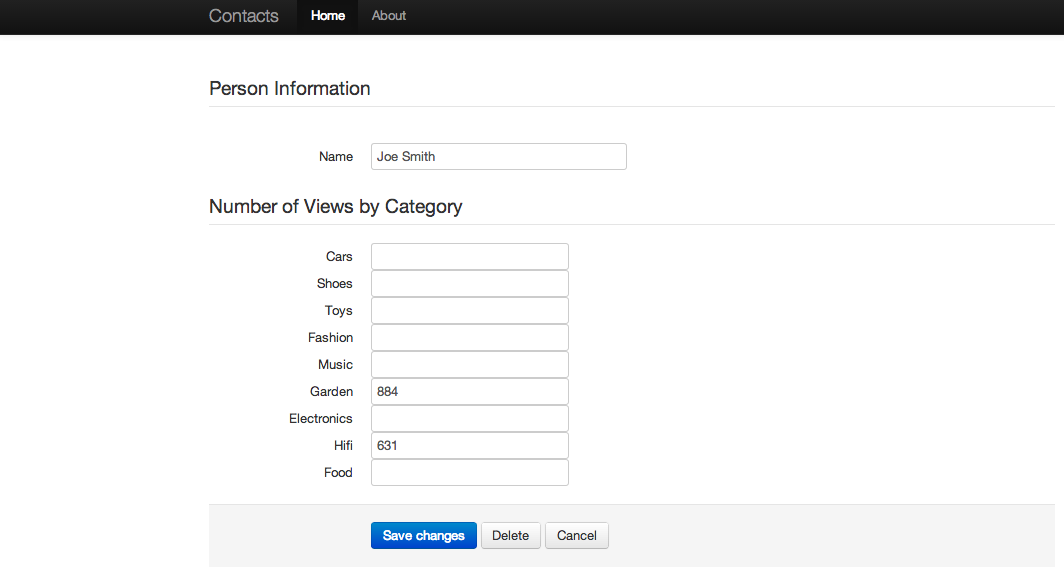
En cliquant sur une personne, vous avez accès aux détails de la personne sélectionnée.
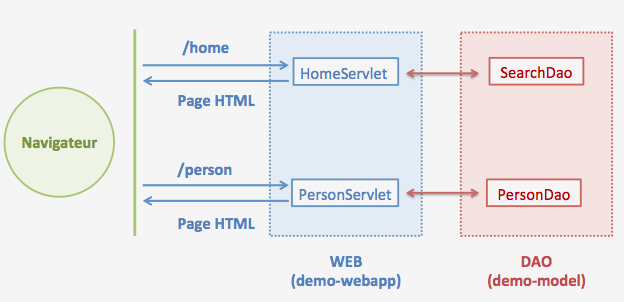
L’application legacy
Cette application se veut legacy. Elle est pilotée par 2 Servlet:
- HomeServlet, gestionnaire de la page d’accueil.
- PersonServlet, pilote de la page de détail d’une personne.
Le mapping URL/servlet configurés dans le fichier web.xml.
Cette application génère l’intégralité de ses pages côté serveur. Les nouvelles générations d’applications Web encouragent :
-
un Web avec de plus en plus d’intelligence côté navigateur.
-
un Web qui pense “application web” avec la même phylosophie qu’une application mobile. Une application qui s’installe dans le navigateur.
-
un Web qui sépare les univers frontend et backend. Il n’est plus question de devoir faire un seul choix technologique pour couvrir l’intégralité de votre besoin. Vous choisissez le meilleur outil pour réaliser votre frontend et vous faites autant pour votre backend. Les deux univers communiquent via HTTP, un protocole particulièrement utile pour faire du web ;)
En phase avec ces principes, la prochaine étape va consister transformer l’existant en application backend exposant des services HTTP/REST.
RESTification de l’application legacy
Pour passer à une architecture REST, commençons par quelque chose de facile : se débarrasser des Servlet de l’application. Supprimer :
- Les classes PersonServlet et HomeServlet.
- Les fichiers suivants qui ne servent plus à rien
demo-webapp/src/main/java/fr/pilato/demo/sql2nosql/webapp/ApplicationInitializer.javaetdemo-webapp/src/main/java/fr/pilato/demo/sql2nosql/webapp/PersonService.java.
L’objectif à présent avec être de réaliser des services REST. Voici les services à réaliser :
1
2
3
4
5
6
7
8
9
10
11
12
13
GET /api/1/person/ => Récupérer toutes les personnes
GET /api/1/person/{id} => Récupérer une personne avec l'identifiant {id}.
PUT /api/1/person/ => Créer une nouvelle personne
PUT /api/1/person/{id} => Mettre à jour la personne ayant l'identifiant {id}
DELETE /api/1/person/{id} => Supprimer la personne ayant l'identifiant {id}
POST /api/1/person/_search => Récupérer des personnes suivant un critière
POST /api/1/person/_init => Initialiser la base de données avec des données exemples
Les puristes du REST pourront ne pas être d’accord avec cette API (l’utilisation de POST pour effectuer une recherche par critères ou encore l’utilisation de PUT au lieu de POST pour créer une nouvelle personne) mais ce n’est pas le sujet, nous allons nous concentrer sur le NoSQL.
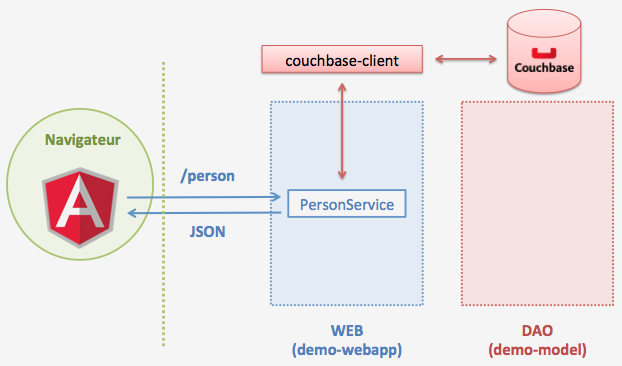
L’application aura l’architecture suivante :
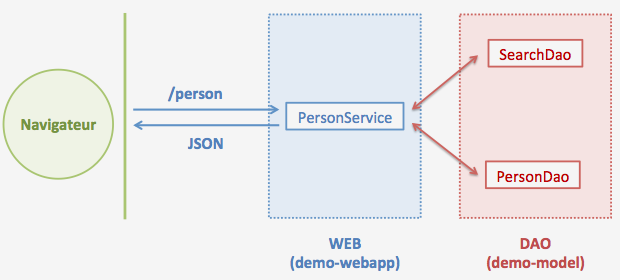
La RESTification sera réalisée avec Spring MVC.
J’ai mis à jour les fichiers :
-
pom.xmlà la racine du projet comme ceci -
demo-webapp/pom.xmlcomme ceci -
demo-webapp/src/main/webapp/WEB-INF/web.xmlpour qu’il ressemble à celui là : web.xml.
J’ai créé le fichier demo-webapp/src/main/java/fr/pilato/demo/sql2nosql/webapp/PersonService.java avec le contenu suivant PersonService.java.
Redémarrage de l’application comme précédemment.
Test du service de récupération de toutes les personnes en accédant à la page suivante via un navigateur moderne : http://localhost:8080/api/1/person/. J’obtiens :
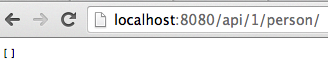
Le résultat [] représente un tableau vide.
Pour initialiser la base de données, il faut utiliser le service
1
POST /api/1/person/_init
Pour effectuer, une requête avec le verbe HTTP POST, vous avez plusieurs possibilités. Le plus simple en environnement Unix est d’utiliser la commande curl comme ceci :
1
curl -XPOST http://localhost:8080/api/1/person/_init
Sinon vous pouvez installer des extensions pour vos navigateurs comme par exemple Simple REST Client pour Chrome ou encore RESTClient pour Firefox.
Une fois les données initialisées, la requête http://localhost:8080/api/1/person/ donne le résultat suivant :
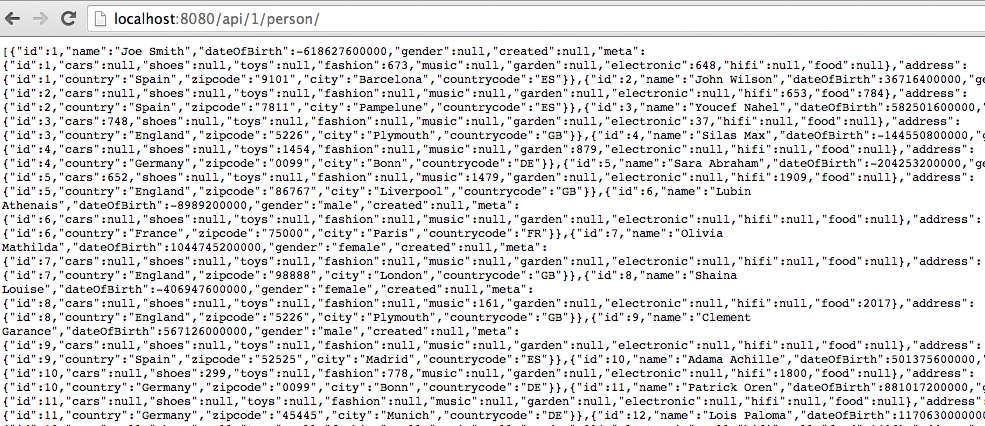
Il s’agit un flux JSON représentant 100 personnes.
Il est possible de tester les autres services développés avec ce même principe avec curl ou encore le super outil que vous avez installé.
Couchbase en action
Maintenant que la partie Web du backend fonctionne, nous allons commencer à quitter le monde SQL en faisant en sorte d’utiliser une base NoSQL. L’heureux élu sera Couchbase.
Couchbase est une base NoSQL orienté document. Il stocke les données sous la forme “clé-valeur”. La clé est une chaine de caractères et la valeur est un document JSON sans aucun schéma pré-défini.
L’architecture de l’application va être modifiée comme ceci :
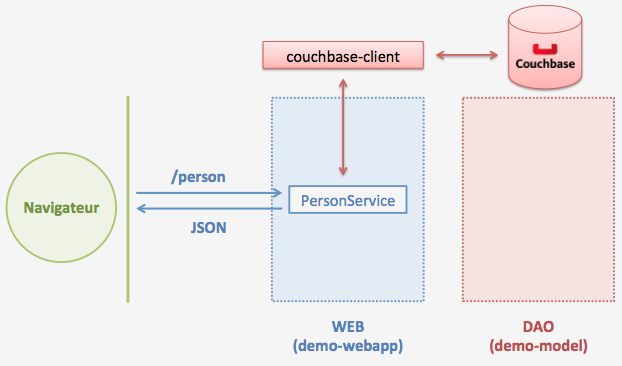
J’ai téléchargé la dernière version (2.2.0) Couchbase Community Edition. Je décompresse l’archive, l’installe puis lance Couchbase.
J’accède à la console d’administration : http://127.0.0.1:8091/index.html :

Et là, sans aucune autre documentation, je me laisse guider en cliquant sur SETUP.
A la page suivante, j’ai laissé les choix par défaut m’invitant à créer un nouveau cluster. J’ai modifié le paramètre Per Server RAM Quota avec la valeur 512 MB au lieu des 3 GB par défaut sur ma machine.
Je laissé les paramètres par défaut et saisis un identifiant/mot de passe administrateur.
Et là, j’ai l’écran suivant :
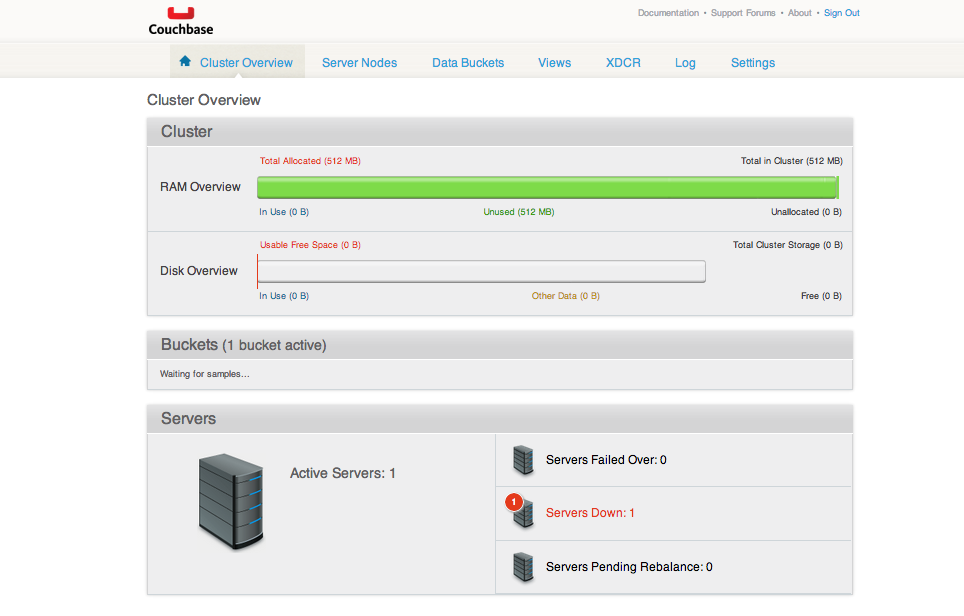
J’ai du rouge. En tant que développeur Java, je suis éduqué pour y voir des erreurs. Je me lance alors dans une tentative de décryptage des couleurs de l’interface d’administration :
-
Pourquoi la phrase Total Allocated (512 MB) est en rouge ? L’indicateur de progression est vert, la phrase Unused 512 MB est en vert. Je conclue qu’il s’agit probablement d’un rouge marquant la criticité d’une ressource et non d’une erreur.
-
Les mots Usable Free Space (O B) en rouge m’inquiète un peu plus. Là encore, j’essai de me rassurer en me disant que Couchbase doit probablement réserver de l’espace disque progressivement et comme je n’ai encore aucune donnée, aucun espace disque n’a encore été réservé.
-
La 3ème indication en rouge est Servers Down : 1. J’ai souvent de l’imagination pour trouver les bons côtés des choses mais là, je n’ai aucune inspiration qui me vient. Je dois avoir un problème !
Alors je clique sur ce message Servers Down : 1.
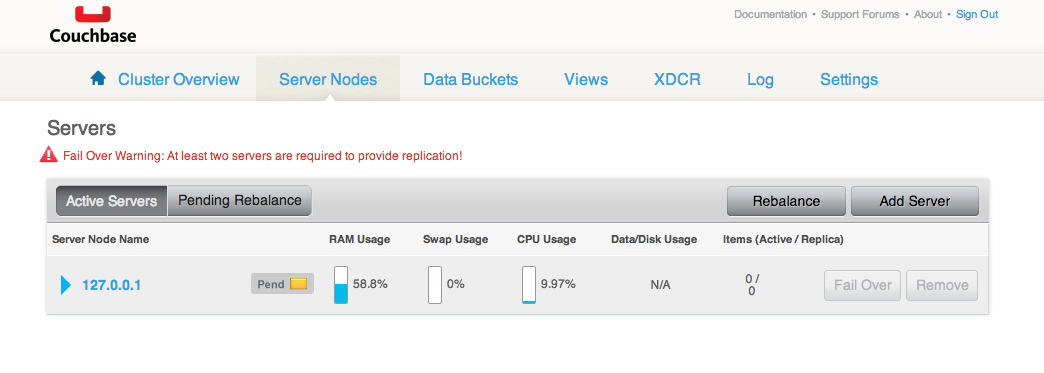
Je décide de laisser en l’état et de compléter l’application pour voir si le client Couchbase a des difficultés à se connecter avec ce Server Down : 1 ;)
Pour communiquer avec Couchbase depuis l’application, nous allons utiliser la bibliothèque couchbase-client accessible via le repository Maven de Couchbase http://files.couchbase.com/maven2/. Il faudrait donc modifier le fichier demo-webapp/pom.xml comme ceci pour ajouter la dépendance vers la librairie couchbase-client.
Ce client est simple d’utilisation, voici un exemple d’utilisation :
1
2
3
4
5
6
7
8
9
// Création de la liste des différents noeuds Couchbase
List<URI> nodes = new ArrayList<URI>();
nodes.add(URI.create("http://127.0.0.1:8091/pools"));
// Création du client
CouchbaseClient client = new CouchbaseClient(nodes, "default", "");
// Récupération d'une donnée dont la clé est "MA_CLE"
String person = (String)client.get("MA_CLE");
Créer le fichier demo-webapp/src/main/java/fr/pilato/demo/sql2nosql/webapp/util/ConnectionManager.java avec ce contenu.
Créer le fichier demo-webapp/src/main/java/fr/pilato/demo/sql2nosql/webapp/util/KeyUtil.java avec ce contenu
Créer le fichier demo-webapp/src/main/java/fr/pilato/demo/sql2nosql/webapp/util/ViewUtil.java avec ce contenu
Compléter le fichier demo-webapp/src/main/java/fr/pilato/demo/sql2nosql/webapp/PersonService.java ce contenu.
Redémarrer l’application.
J’obtiens une jolie stacktrace. Ah voilà quelque chose qui me parle !
1
2
3
4
5
6
7
Caused by: org.springframework.beans.BeanInstantiationException: Could not instantiate bean class [fr.pilato.demo.sql2nosql.webapp.PersonService]: Constructor threw exception; nested exception is com.couchbase.client.vbucket.config.ConfigParsingException: Number of buckets must be a power of two, > 0 and <= 65536
at org.springframework.beans.BeanUtils.instantiateClass(BeanUtils.java:163)
at org.springframework.beans.factory.support.SimpleInstantiationStrategy.instantiate(SimpleInstantiationStrategy.java:87)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.instantiateBean(AbstractAutowireCapableBeanFactory.java:1004)
... 54 more
Caused by: com.couchbase.client.vbucket.config.ConfigParsingException: Number of buckets must be a power of two, > 0 and <= 65536
at com.couchbase.client.vbucket.config.DefaultConfigFactory.parseEpJSON(DefaultConfigFactory.java:135)
Euh finalement, ça ne me parle pas tant que ça ;)
Je porte mon attention sur le message d’erreur Number of buckets must be a power of two, > 0 and <= 65536. Après plusieurs investigations dans différents forums là, là, ou encore là. Je croise même un message de Tugdual dans ces fils de discussion ;)
Après avoir cliqué sur tous les menus et tous les boutons de l’interface d’administration, je ne parviens toujours pas à avancer. J’ai réussi au passage à me débarrasser du message d’avertissement Fail Over Warning : At least two servers are required to provide replication! en supprimant et recréant un bucket. Je comprends que j’ai eu ce message d’erreur car lors de l’initialisation de Couchbase, la case à cocher Replicate est cochée par défaut. Par contre impossible de me débarrasser de l’erreur Server Down : 1.
J’ai essayé une version plus récente du client. Je remarque au passage que le client couchbase-client est disponible en fait dans le Repo Maven Central via la dépendance :
1
2
3
4
5
<dependency>
<groupId>com.couchbase.client</groupId>
<artifactId>couchbase-client</artifactId>
<version>1.2.2</version>
</dependency>
Quoiqu’il en soit, cela ne résoud pas le problème !
Je décide alors de recommencer l’installation. Je n’ai pas trouvé un moyen de revenir à l’état initial via l’interface d’administration. J’arrête le serveur, je supprime tous les fichiers générés par Couchbase puis je démarre Couchbase. Cette fois-ci je choisis 1024 MB pour la RAM, je désactive la réplication et je sélectionne un échantillon de données (beer). Et là, c’est magique plus de Server Down : 1 !
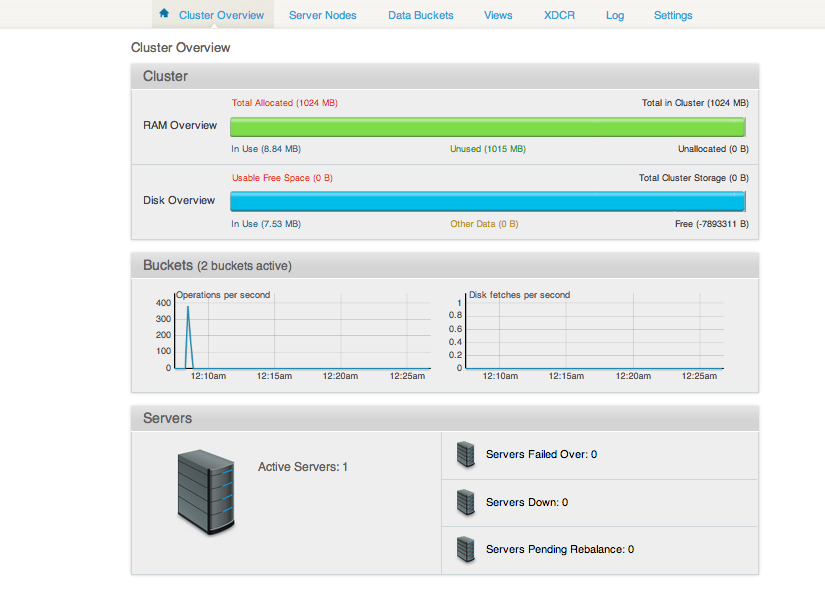
Je redémarre l’application, plus d’exception !
Rechargement des données
1
curl -XPOST http://localhost:8080/api/1/person/_init
Les données sont accessibles via l’url http://localhost:8080/api/1/person/.
Dans l’interface d’administration, à l’onglet View, il y a une vue by_name qui permet de visualiser quelques données. Oui les données ont bien été insérées dans Couchbase.
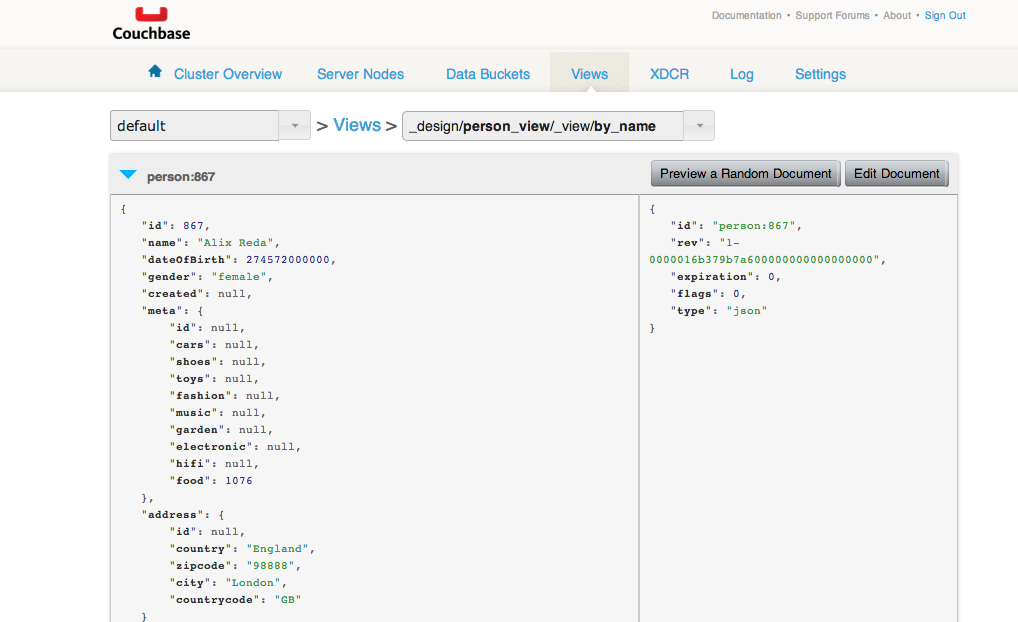
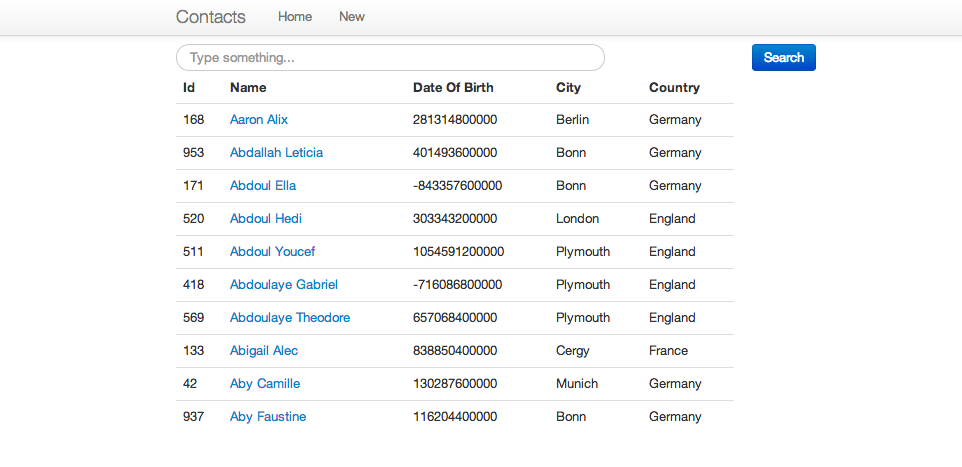
Les écrans avec AngularJS et Twitter Bootstrap
Nous avons jusqu’à présent un backend qui renvoie des données au format JSON. Cette étape va consister à recréer les vues que nous avions au départ.
Pour ne pas trop alourdir cet article, je ne vais pas faire un cours sur AngularJS qui n’est pas le sujet principal de cette session ;)
Vous pouvez directement retrouver les sources dans la branche 04-angular/end ou bien les télécharger directement ici.
Redémarrer l’application.
Les écrans sont de retour.
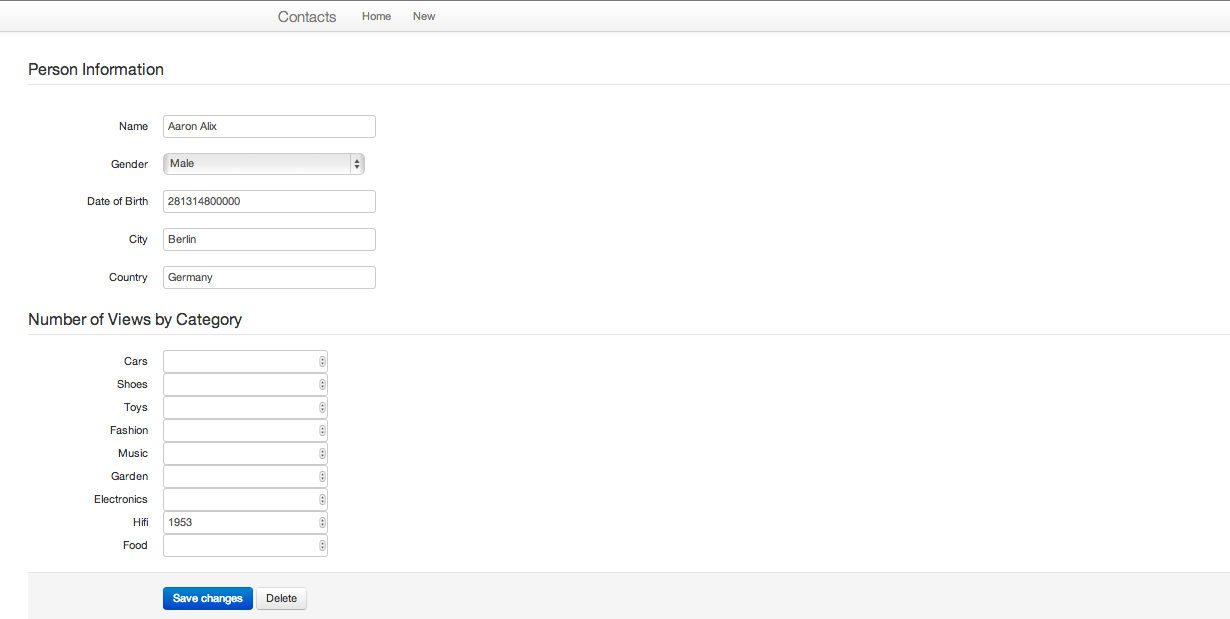
Il n’est pour le moment possible que d’effectuer des recherches par nom.
La recherche full text
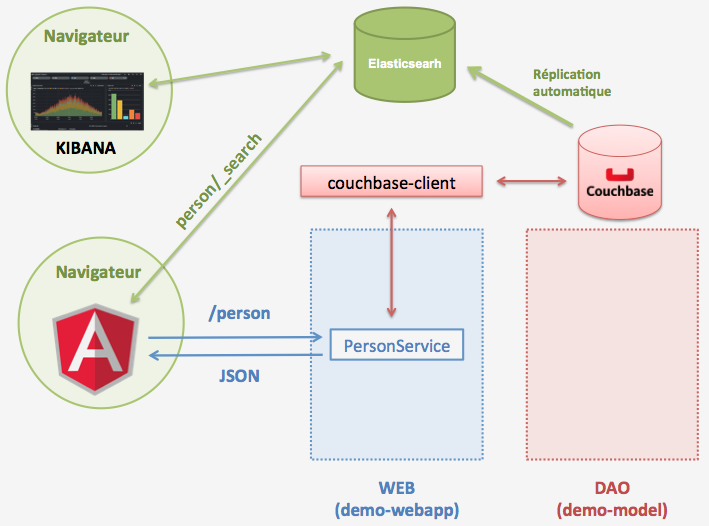
La recherche full text va être implémentée avec Elasticsearch. L’idée principale est d’avoir les données répliquées de Couchbase à Elasticsearch qui va les indéxer. L’application front end, pour rechercher les données, va directement intéroger Elasticsearch.
Nous aurons à la fin de cette étape, l’architecture suivante :
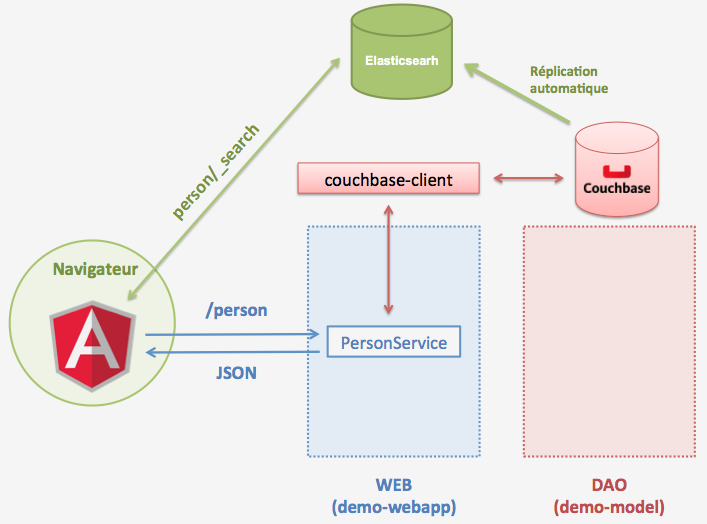
Je télécharge Elasticsearch v0.90.2 et décompresser l’archive dans le répertoire de votre choix.
J’installe le plugin Couchbase pour Elasticsearch (version 1.1.0) via l’exécutable bin/plugin(.bat).
1
bin/plugin -install transport-couchbase -url http://packages.couchbase.com.s3.amazonaws.com/releases/elastic-search-adapter/1.1.0/elasticsearch-transport-couchbase-1.1.0.zip
Dans le fichier config/elasticsearch.yml, je renseigne les paramètres :
1
2
3
couchbase.username: Administrator
couchbase.password: Administrator
couchbase.maxConcurrentRequests: 256
Je démarre Elasticsearch.
1
bin/elasticsearch -f
Je crée un template Elasticsearch.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
curl -XPUT http://localhost:9200/_template/couchbase -d '
{
"template" : "*",
"order" : 10,
"mappings" : {
"couchbaseCheckpoint" : {
"_source" : {
"includes" : ["doc.*"]
},
"dynamic_templates": [
{
"store_no_index": {
"match": "*",
"mapping": {
"store" : "no",
"index" : "no",
"include_in_all" : false
}
}
}
]
},
"_default_" : {
"properties" : {
"meta" : {
"type" : "object",
"enabled" : false
}
}
}
}
}
'
Je crée un index pour person.
1
curl -XPUT http://localhost:9200/person
Je reviens à l’interface d’administration Couchbase : http://127.0.0.1:8091/index.html.
Je clique sur l’onglet XDCR.
Je crée un cluster de référence avec le bouton Create Cluster Reference.
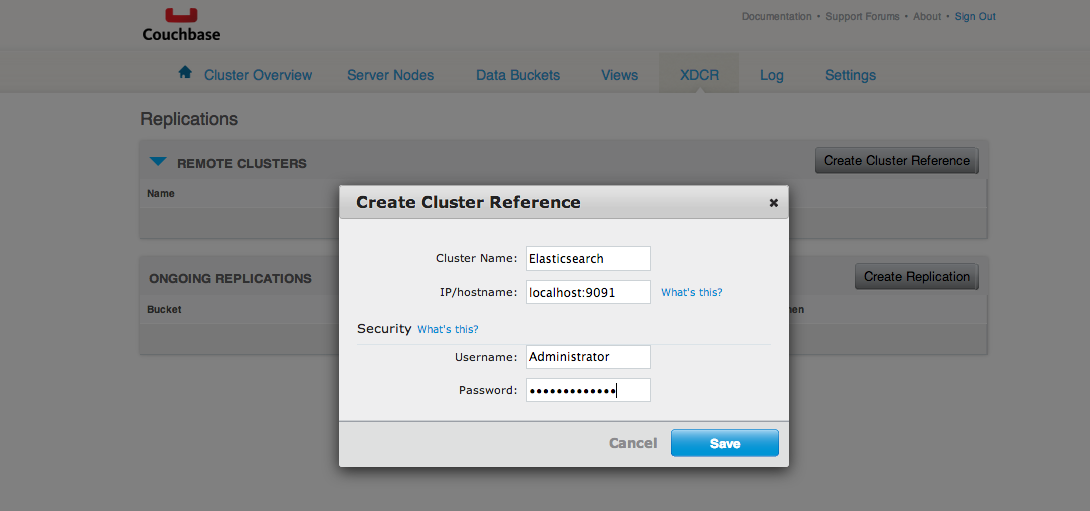
Je crée une réplication avec le bouton Create Replication.
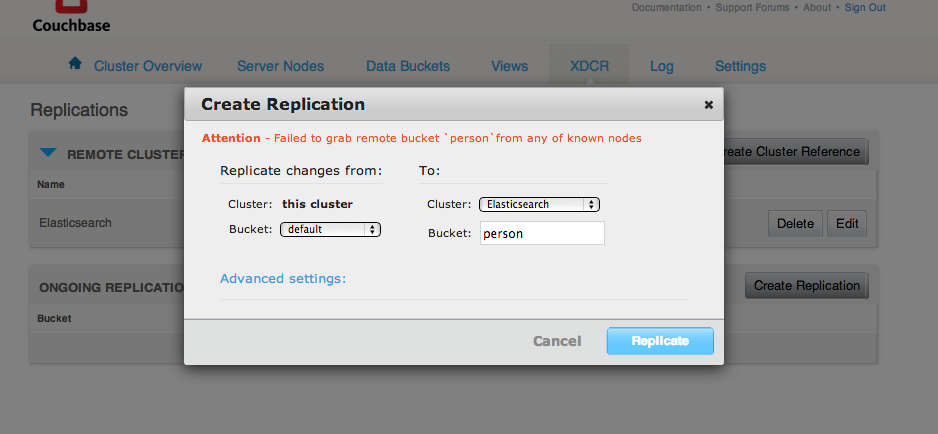
Et là dans mon cas, ça n’a pas fonctionné.
Après quelques recherches, je suis tombé sur cette fil de discussion qui conseille l’utilisation de la version 1.2.0 du plugin pour ma version de Couchbase.
Je désinstalle de l’ancienne version du plugin.
1
bin/plugin -remove transport-couchbase
J’installe la version 1.2.0 du plugin.
1
bin/plugin -install transport-couchbase -url http://packages.couchbase.com.s3.amazonaws.com/releases/elastic-search-adapter/1.2.0/elasticsearch-transport-couchbase-1.2.0.zip
Je réessaie de créer la réplication et j’ai toujours la même erreur. Côté Elasticsearch, je peux lire l’exception suivante dans les logs :
1
2
3
013-11-23 02:30:02,779][WARN ][org.eclipse.jetty.servlet.ServletHandler] Error for /pools/default/buckets
java.lang.NoSuchMethodError: org.elasticsearch.cluster.metadata.MetaData.getIndices()Ljava/util/Map;
at org.elasticsearch.transport.couchbase.capi.ElasticSearchCouchbaseBehavior.getBucketsInPool(ElasticSearchCouchbaseBehavior.java:82)
Je comprends que ma version d’Elasticsearch n’est pas compatible avec la nouvelle version du plugin.
J’ai trouvé le tableau de compatibilité suivant qui rend clair tous mes problèmes d’incompatibilité accessible ici :
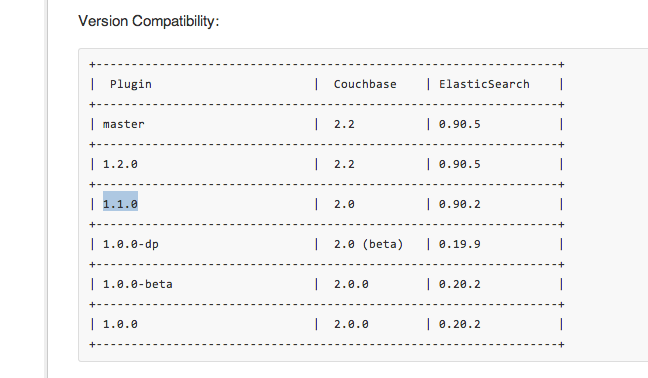
Tugdual et David ont travaillé sur la ligne Plugin=1.1.0, Couchbase=2.0, ElasticSearch=0.90.2.
Vu que j’ai une base Couchbase qui fonctionne et que comme tout développeur j’aime bien les dernières versions, je vais télécharger ElasticSearch 0.90.5 et recommencer l’installation.
J’obtiens toujours la même erreur lors de la création de la réplication même avec les dernières versions. Par un geste de désespoir je supprime et recrée le cluster de référence. Et là, la création de la réplication se fait sans problème !
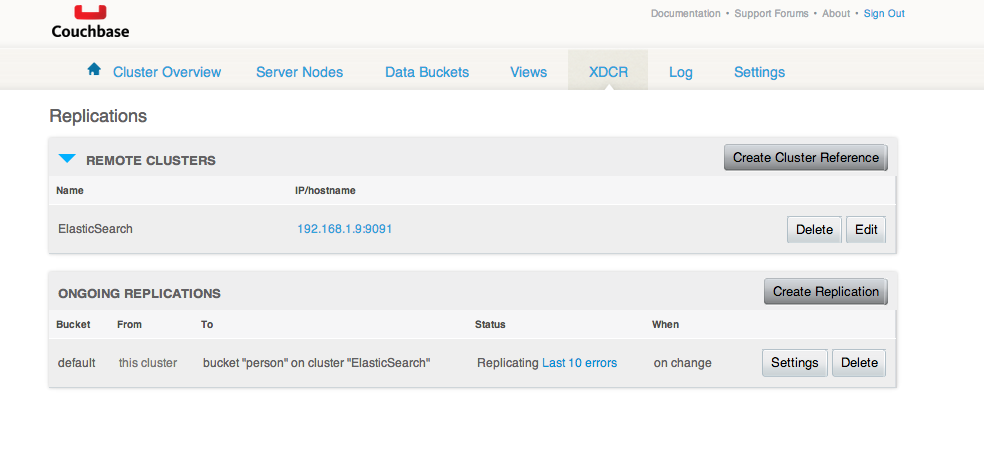
Mais… Il y a un petit message que je n’ai pas envie de voir Last 10 errors. Je clique sur ce message de couleur bleu.
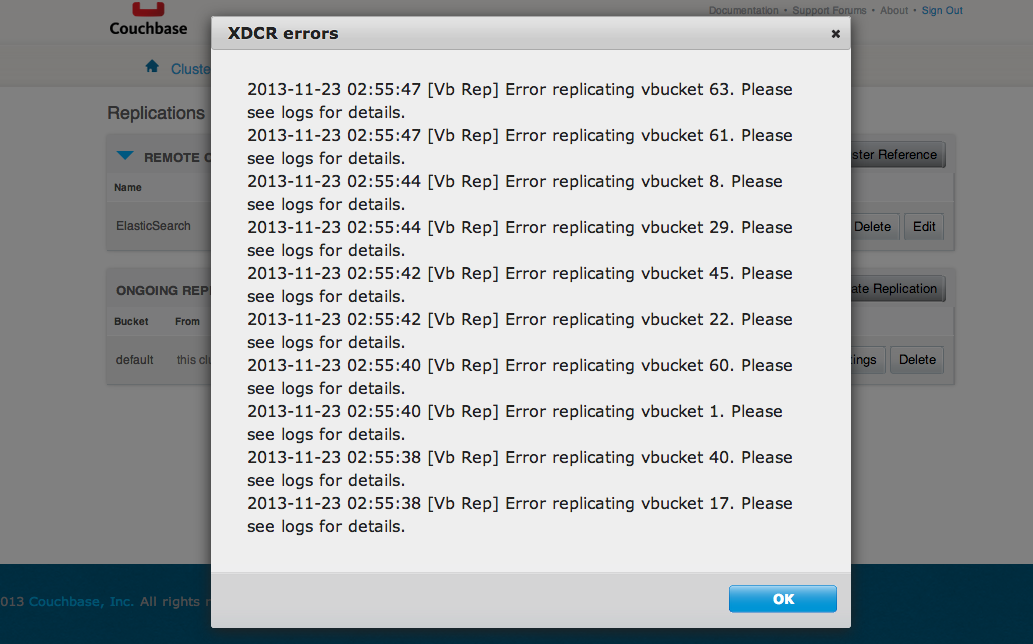
Là je ne sais pas trop quoi penser ;) La réplication ne se passe visiblement pas bien.
Je décide de faire une courte pause, de télécharger la version 2.0.0 de Couchbase et de revenir à la version 0.90.2 d’Elasticsearch.
Je démarre la version 2.0.0 de Couchbase, elle rentre en conflit avec ma version 2.2.0 installée précédemment car elles partagent le même répertoire de travail. Je déplace ce répertoire de travail et là plus de problème.

Je réinjecte les données :
1
2
curl -XPOST http://localhost:8080/api/1/person/_init

Les données sont bien répliquées, on est passé de 1001 à 2001 comme prévu.
Le client AngularJS sera modifié pour interroger directement Elasticsearch pour la fonctionnalité de recherche. Elasticsearch expose une API REST pour rechercher des données. Pour rechercher les personnes ayant ‘Alix’ dans leur nom ou prénom, il suffit d’accéder à l’adresse : http://127.0.0.1:9200/person/_search?q=alix.
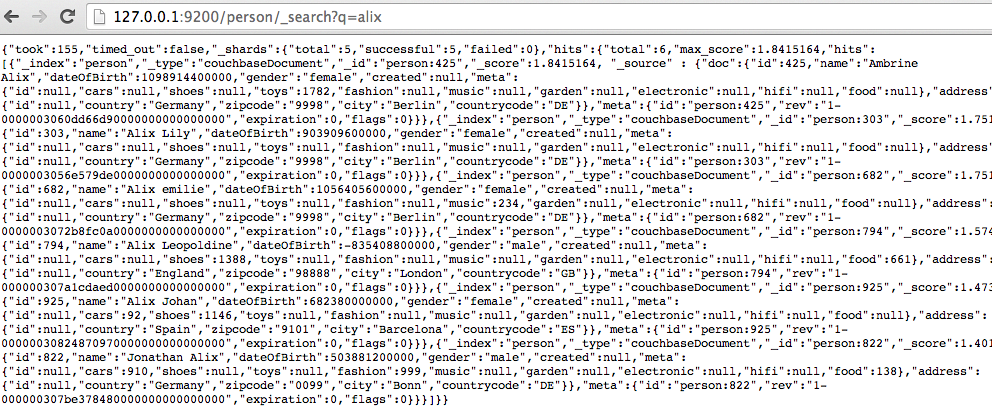
Vos tableaux de bord les doigts dans le nez avec Kibana
Kibana est une application web qui permet de visualiser les données indexées dans Elasticsearch suivant des critères.
A l’issue de cette étape, l’architecture de l’application va ressembler à ceci :
J’installe le plugin Kibana pour Elasticsearch.
1
bin/plugin -install elasticsearch/kibana
En lançant Kibana, http://localhost:9200/_plugin/kibana/, j’obtiens ceci :
Je choisis de ne pas tenter l’aventure de la mise à jour. Je clique sur le lien src et j’accède à une page d’introduction.
Je clique sur Sample Dashboard.
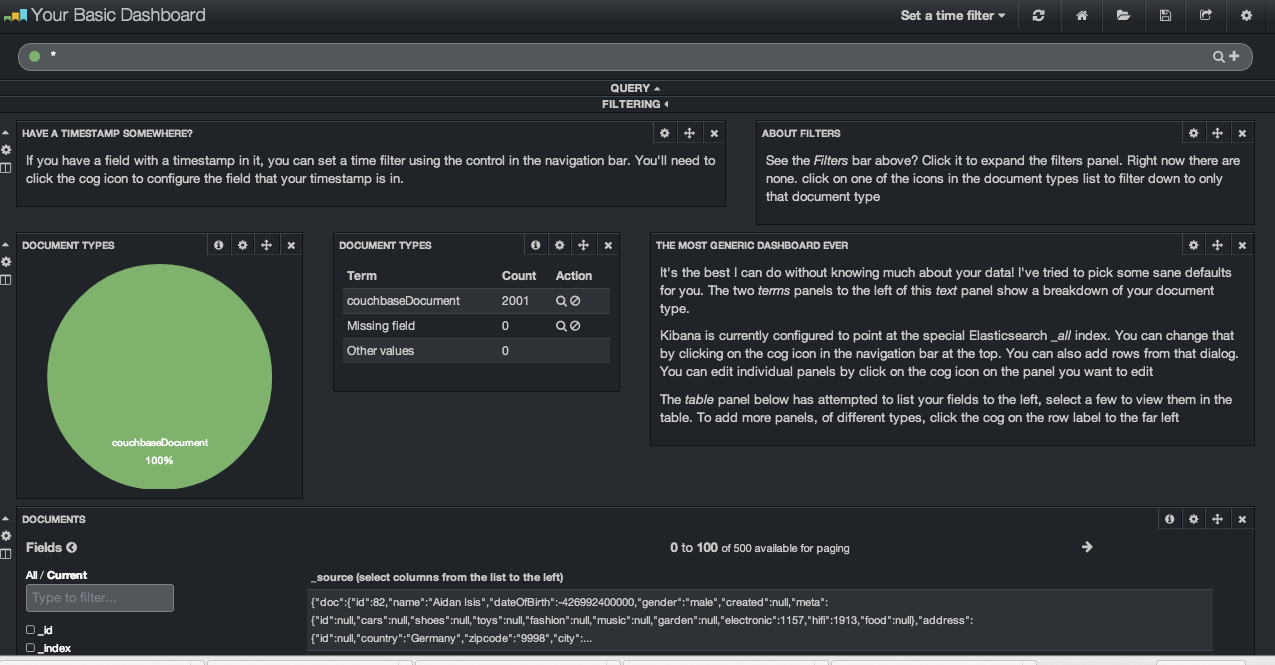
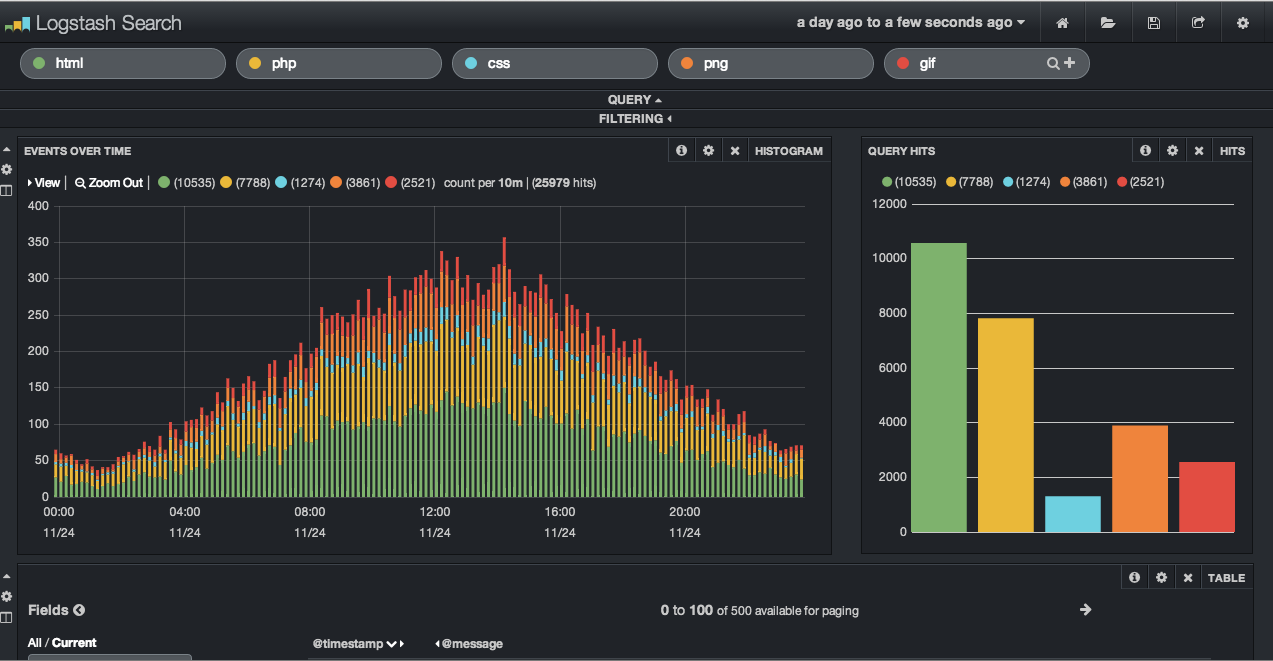
Il est possible de filtrer, visualiser les données suivant plusieurs axes d’analyse. Si vous souhaitez jouer avec Kibana, il y a une démo en ligne accessible à l’adresse http://demo.kibana.org/#/dashboard :
Les slides de Devoxx Belgique 2013
Et pour conclure ?
Comme vous l’avez surement constaté, cette soirée du JUG Nantes a été riche en contenu.
Dans le monde des bases de données NoSQL orientées document, Couchbase a un concurrent direct MongoDB. Un participant va poser la question de savoir quelles étaient les différences de fond entre ces deux bases de données. Tugdual, évangéliste Couchbase, va donner les éléments de réponse suivants :
-
Couchbase est conçu pour faciliter la distribution des données, la création de nombreux clusters de données via une interface d’administration. Il est donc plus indiqué pour des systèmes nécessitant de traitement de grand volumes de données distribuées sur plusieurs machine. Créer un cluster avec MongoDB ne serait pas une tâche aussi simple que dans Couchbase.
-
MongoDB est plus riche et plus facile à requêter que Couchbase. Il dispose d’une API très puissante pour extraire des données. C’est pour cette raison qu’il est conseillé de coupler Couchbase à Elasticsearch pour disposer d’une plus grande puissance d’extraction/analyse de données.
Au regard de la complémentarité des deux technologies (Couchbase & Elasticsearch), on peut se demander A quand le rachat de l’un par l’autre ?. David va affirmer, hors séance, que ce n’était pas à sa connaissance à l’ordre du jour. Il y voit en Elasticsearch un produit complet au point que certains clients n’hésiteraient pas à l’utiliser directement en tant que base de données.
Bien évidemment, si vous souhaitez mettre en oeuvre ces outils, prenez des versions compatibles entre elles et n’hésitez pas à recommencer quand vous êtes dans une impasse ;)
Je ne sais pas pour vous mais je suis impatient d’être à la prochaine soirée du JUG Nantes : Grails dans les tranchés + Java 8.
 Tu souhaites être informé des prochaines formations ? Inscris-toi !
Tu souhaites être informé des prochaines formations ? Inscris-toi !